重构是对软件内部结构的一种调整,目的是在不改变软件之可察性前提下,提高其可理解性,降低其修改成本。关于重构的至理明言如下:
任何一个傻瓜都能写出计算器可以理解的代码,唯有写出人类容易理解的代码,才是优秀的程序员; 事不过三,三则重构; 当你接获bug提报,请先撰写一个单元测试来揭发这个bug; 当你感觉需要撰写注释,请先尝试重构,试着让所有的注释变得多余; 当你发现自己需要为程序增加一个特性,而代码结构使你无法方便的这样做,就先重构那个程序; 重构之前,必须建立一套可靠的测试机制; 写软件就像种树,优秀的程序员挖成小坑后随及填好,继续挖下一个,只会产生一系列小坑,不会有大坑,菜鸟则不会意识到所挖的坑正在变大,还是不停的挖,直到自己掉进大坑,爬不出来,陷入无尽的痛苦深渊; 开发时间越长,越能体会垃圾代码的痛苦,却不知道如何改进; Kent Beck:我不是一个伟大的程序员,我只是个有着一些优秀习惯的好程序员而已;
变量(Variable)
不要定义一个临时变量多次重复使用,临时变量定义仍然应该可以自解释,从变量名称能够很好的理解变量的含义和作用。在定义一个临时变量后需要有一段业务逻辑才能够完成对临时变量的赋值的时候,可以考虑将这段逻辑抽取到一个独立的方法。
doublegetPrice(){
int basePrice = _quantity* _itemPrice;
double discountFactor;
if (basePrice > 1000) discountFactor = 0.95;
else discountFactor = 0.98;
return basePrice * discountFactor;
}
重构为:
double getPrice(){
return basePrice()* discountFactor();
}
private int basePrice(){
return _quantity* _itemPrice;
}
private double discountFactor(){
if (basePrice()> 1000) return0.95;
else return 0.98;
}
当遇到复杂的表达式的时候,需要引入解释变量,因为复杂的表达式很难进行自解释。
if ((platform.toUpperCase().indexOf("MAC")> -1)&&
(browser.toUpperCase().indexOf("IE")> -1)&&
wasInitialized()&& resize> 0 )
{
// do something
}
重构为:
final booleanisMacOs = platform.toUpperCase().indexOf("MAC")>-1;
final boolean isIEBrowser =browser.toUpperCase().indexOf("IE") > -1;
final booleanwasResized = resize >0;
if (isMacOs&& isIEBrowser&& wasInitialized()&& wasResized){
// do something
}
减少对全局变量的使用,第一个是全局变量的生命周期很难控制,资源本身无法得到很快的释放,其二是过多使用全局变量导致在调用方法的时候很难完全清楚方法说需要的入口数据信息,其三,多处都可以对全局变量赋值,我们很难立刻定位到当前全局变量的值来源自哪里?
分解方法(Extract Method)
一个较大的方法往往也会分为多个小的段落,step1,step2,step3,在每一个步骤都会考虑添加注释说明。而这些相对较为独立的步骤就可以分解为不同的方法,在分解后方法名可以自解释方法的功能而不再需要额外的注释。在一个类里面如果方法里面有一段代码在多个方法中重复出现,需要抽取该类的公用方法。在多个不同的类中有一段代码重复出现,需要考虑将公用代码放到公用类中形成公用方法。
方法名需要很好的自解释方法的功能,方法的返回尽量单一,方法的入口参数太多的时候应该考虑使用集合,结构或数据对象进行参数的传递。参数的传递可能出传递的是引用,但不要去修改入口参数的值。
不要因为一个方法里面只有一行,两行很短而不考虑去分解,分解的时候更多的是考虑代码的自解释性。代码本身不是解释的技术实现机制,而是解释的业务规则和需求。如果代码不是解释的业务规则和需求,那么其它人员就很难快速理解。
引入方法对象来取代方法,当发现一个方法只用到该类里面的几个关键属性,方法和类里面其它的方法交互很少,输出单一。由于该方法和这几个属性内聚性很强而和该类其它部分松耦合,因此可以考虑将方法和这部分属性移出形成一个单独的方法对象。
移动方法,类的职责要单一,一个类的方法更多用到了别的类的属性,这个方法可能更适合定义在那个类中。
class Account...
private AccountType_type;
private int_daysOverdrawn;
double overdraftCharge(){
if (_type.isPremium()){
double result = 10;
if (_daysOverdrawn > 7) result += (_daysOverdrawn -7)* 0.85;
return result;
}
else return _daysOverdrawn * 1.75;
}
double bankCharge(){
double result = 4.5;
if (_daysOverdrawn > 0) result +=overdraftCharge();
return result;
}
重构为:
classAccount...
private AccountType _type;
private int _daysOverdrawn;
double overdraftCharge(){
return _type.overdraftCharge(_daysOverdrawn);
}
double bankCharge(){
double result = 4.5;
if (_daysOverdrawn > 0)
result += _type.overdraftCharge(_daysOverdrawn);
return result;
}
classAccountType...
double overdraftCharge(Account account){
if (isPremium()){
double result = 10;
if (account.getDaysOverdrawn()> 7)
result += (account.getDaysOverdrawn()- 7)* 0.85;
return result;
}
else return account.getDaysOverdrawn()* 1.75;
}
分解类(Extract Class)
类的职责的划分不容易在初次设计时就准确把握,所以在编码时重构是必要的。职责定位不清!——典型特征是拥有太多的成员变量;而在这里面最重要的就是职责要单一,属性和方法是否合适的类中。如果不是就需要考虑分解或合并,扩展类的功能,或者抽象相应的接口。面向对象的设计原则如下:
1.单一职责原则(SRP)-就一个类而言,应该仅有一个引起它变化的原因
类的职责要单一,类里面的方法只做类的职责范围里面的事情。MVC即是一种粗粒度的职责话费,模型类重点是提供数据,控制类重点是处理业务逻辑,而V视图类则是关注数据获取后的呈现。
数据和数据操作可以考虑分解,如形成专门的DTO数据传输对象类。界面类和界面数据提供类也可以考虑分离,如形成专门的Facade层专门负责数据的准备和形成。界面层不应该有太多的数据处理操作。
当发现一个大的类里面的属性和方法存在明细的分组特性的时候,而且分组直接松散耦合,需要考虑分解为多个类。
引入方法对象来取代方法,当发现一个方法只用到该类里面的几个关键属性,方法和类里面其它的方法交互很少,输出单一。由于该方法和这几个属性内聚性很强而和该类其它部分松耦合,因此可以考虑将方法和这部分属性移出形成一个单独的方法对象。
胖接口也是违反职责单一,胖接口会导致所有实现接口的类都Override所有的接口方法,而有些接口方法往往是子类并不需要的。因此对于胖接口仍然要从职责的角度对接口进行拆分。
2.开放——封闭原则(OCP)-对扩展开放,对修改封闭
当发生变化时,只需要添加新的代码,而不必改动已经正常运行的代码:软件人的梦想!而要达到这个目的,关键是要能够较为准确的预测业务变化会导致的可能会发送变化的模块或代码。
3.Liskov替换原则(LSP)
子类型必须能够替换掉他们的基类型。正是子类型的可替换性,才使得使用基类类型的软件无须修改就可以扩展。案例参考正方形驳论。矩形的合理假设:长、宽可以独立变化;而正方形的合理假设:长、宽始终相等。因此正方形并不能从矩形继承。
4.依赖倒置原则(DIP)-高层模块不应该依赖于低层模块;抽象不应该依赖于细节。
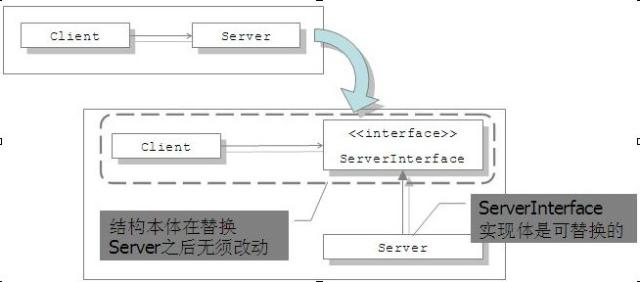
依赖倒置原则的重点是高层模块类不要去依赖底层模块的类,而应该去依赖接口,特别是当我们预见到底层模块的类本身可能会扩展和变化的时候。这样在变化的时候最大的好处就是高层类和接口不用变化。
类是否考虑抽象为接口,一方面是根据LSP原则进行重构,一方面是需要观察我们建立的类,是否有多个类本身存在相同的行为或方法,如果存在则需要考虑抽象接口。